Turborepo 0.4.0
- Name
- Jared Palmer
- X
- @jaredpalmer
I'm excited to announce the release of Turborepo v0.4.0!
- 10x faster:
turbohas been rewritten from the ground up in Go to make it even more blazing fast - Smarter hashing: Improved hashing algorithm now considers resolved dependencies instead of just the contents of the entire root lockfile
- Partial lockfiles / sparse installs: Generate a pruned subset of your root lockfile and monorepo that includes only the necessary packages needed for a given target
- Fine-grained scheduling: Improved task orchestration and options via
pipelineconfiguration - Better cache control: You can now specify cache outputs on a per-task basis
Rewritten in Go
Although I initially prototyped turbo in TypeScript, it became clear that certain items on the roadmap would require better performance. After around a month or so of work, I'm excited to finally release Go version of the turbo CLI. Not only does it boot in a milliseconds, but the new Go implementation is somewhere between 10x and 100x faster at hashing than the Node.js implementation. With this new foundation (and some features you're about to read about), Turborepo can now scale to intergalactic sized projects while remaining blazing fast all thanks to Go's awesome concurrency controls.
Better Hashing
Not only is hashing faster in v0.4.0, but also a lot smarter.
The major change is that turbo no longer includes the hash of the contents of the root lockfile in its hasher (the algorithm responsible for determining if a given task exists in the cache or needs to be executed). Instead, turbo now hashes the set of the resolved versions of a package's dependencies and devDependencies based on the root lockfile.
The old behavior would explode the cache whenever the root lockfile changed in any way. With this new behavior, changing the lockfile will only bust the cache for those package's impacted by the added/changed/removed dependencies. While this sounds complicated, again all it means is that when you install/remove/update dependencies from npm, only those packages that are actually impacted by the changes will need to be rebuilt.
Experimental: Pruned Workspaces
One of our biggest customer pain points/requests has been improving Docker build times when working with large Yarn Workspaces (or really any workspace implementation). The core issue is that workspaces' best feature--reducing your monorepo to a single lockfile--is also its worst when it comes to Docker layer caching.
To help articulate the problem and how turbo now solves it, let's look at an example.
Say we have a monorepo with Yarn workspaces that includes a set of packages called frontend, admin, ui, and backend. Let's also assume that frontend and admin are Next.js applications that both depend on the same internal React component library package ui. Now let's also say that backend contains an Express TypeScript REST API that doesn't really share much code with any other part of our monorepo.
Here's what the Dockerfile for the frontend Next.js app might look like:
While this works, there are some things that could be a lot better:
- You manually
COPYin the internal packages and files needed to build the target app and need to remember which need to be built first. - You
COPYthe rootyarn.locklockfile into the correct position very early in the Dockerfile, but this lockfile is the lockfile for the entire monorepo.
This last issue is especially painful as your monorepo gets larger and larger because any change to this lockfile triggers a nearly full rebuild regardless of whether or not the app is actually impacted by the new/changed dependencies.
....until now.
With the all new turbo prune command, you can now fix this nightmare by deterministically generating a sparse/partial monorepo with a pruned lockfile for a target package--without installing your node_modules.
Let's look at how to use turbo prune inside of Docker.
So what exactly is the output of the turbo prune? A folder called out with the following inside of it:
- A folder
jsonwith the pruned workspace's package.jsons - A folder
fullwith the pruned workspace's full source code, but only including the internal packages that are needed to build the target - A new pruned lockfile that only contains the pruned subset of the original root lockfile with the dependencies that are actually used by the packages in the pruned workspace.
Thanks to the above, Docker can now be set up to only rebuild each application when there is a real reason to do so. So frontend will only rebuild when its source or dependencies (either internal or from npm) have actually changed. Same same for admin and backend. Changes to ui, either to its source code or dependencies, will trigger rebuilds of both frontend and admin, but not backend.
While this example seems trivial, just imagine if each app takes up to 20 minutes to build and deploy. These savings really start to add up quickly, especially on large teams.
Pipelines
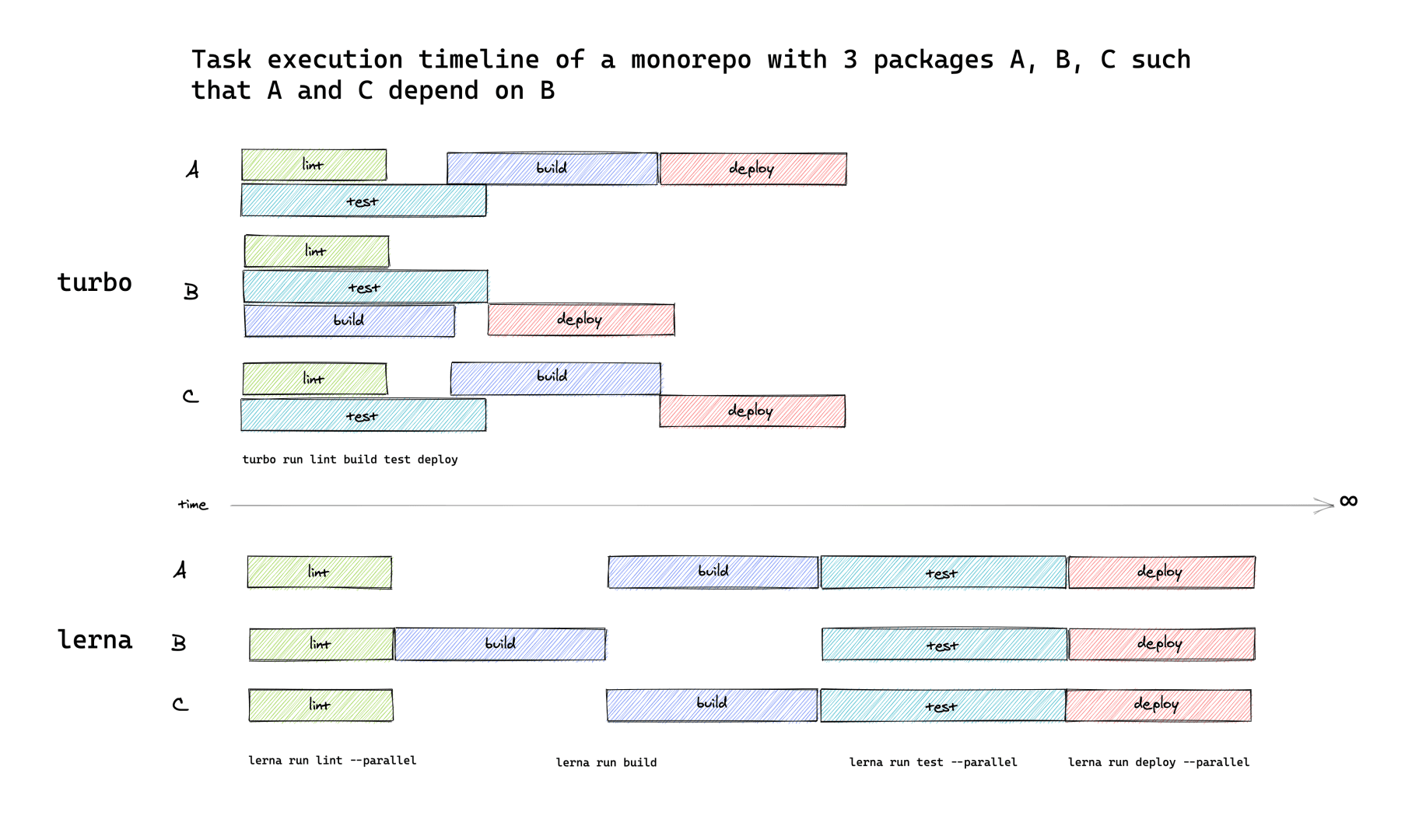
To give you even more control over your Turborepo, we've added pipeline to turbo's configuration. This new field in lets you specify how the npm scripts in your monorepo relate to each other as well as some additional per-task options. turbo then uses this information to optimally schedule your tasks in your monorepo, collapsing waterfalls that would otherwise exist.
Here's how it works:
The above config would then be interpreted by turbo to optimally schedule execution.
What's that actually mean? In the past (like Lerna and Nx), turbo could only run tasks in topological order. With the addition of pipelines, turbo now constructs a topological "action" graph in addition to the actual dependency graph which it uses to determine the order in which tasks should be executed with maximum concurrency. The end result is that you no longer waste idle CPU time waiting around for stuff to finish (i.e. no more waterfalls).
Improved Cache Control
Thanks to pipeline, we now have a great place to open up turbo's cache behavior on a per-task basis.
Building on the example from above, you can now set cache output conventions across your entire monorepo like so:
Note: Right now, pipeline exists at the project level,
but in later releases these will be overridable on per-package basis.
What's Next?
I know this was a lot, but there's even more to come. Here's what's up next on the Turborepo roadmap.
- A landing page!
- Remote caching w/
@turborepo/server - Build scans, telemetry, and metrics and dependency and task graph visualization
- Desktop Console UI
- Intelligent
watchmode - Official build rules for TypeScript, React, Jest, Node.js, Docker, Kubernetes, and more
Credits
- Iheanyi Ekechukwu for guiding me through the Go ecosystem
- Miguel Oller and the team from Makeswift for iterating on the new
prunecommand